


"Teleskope helps you understand what's wrong with your data access governance and tells you what to do about it."
Purview's classification is primarily regex and keyword-based — it finds things that look like known sensitive data types. It works reasonably well for standard PII but generates significant false positives in complex environments and cannot classify business-specific sensitive data without extensive custom rule-writing. Teleskope's classification engine uses multi-stage machine learning with contextual understanding — it learns your environment and classifies what's actually risky in your specific context. Many Teleskope customers run both: Teleskope provides accurate classification, which feeds Purview with reliable MIP labels that dramatically improve Purview's enforcement accuracy.
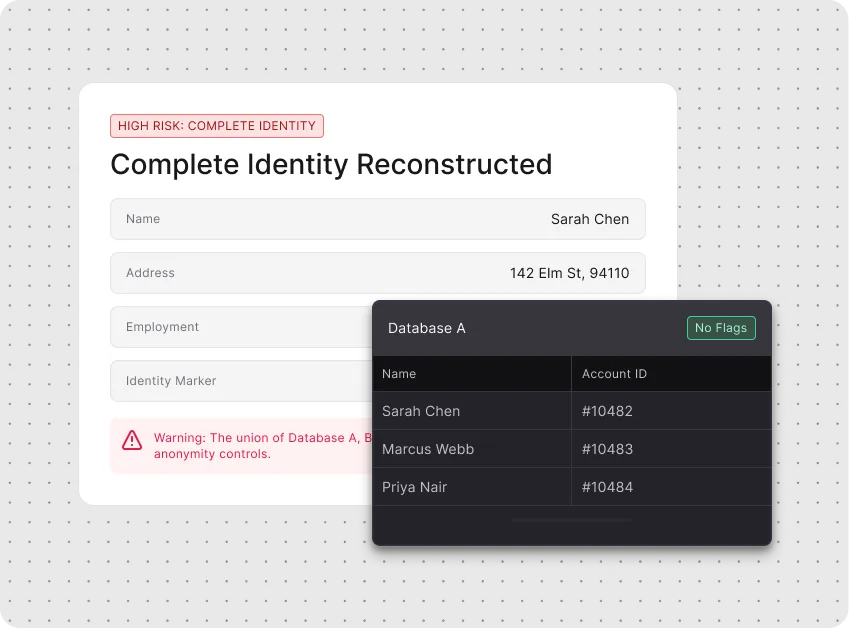
Yes — and this is one of the areas where Teleskope most clearly outperforms signature-based tools. Standard classifiers fail in customized environments because they rely on field names and data structures that match their training data. Teleskope's classification engine understands data in context — it reads what data means, not just what it looks like, which is why it works in custom Salesforce configurations, homegrown CRMs, and non-standard database architectures where other tools fail entirely.
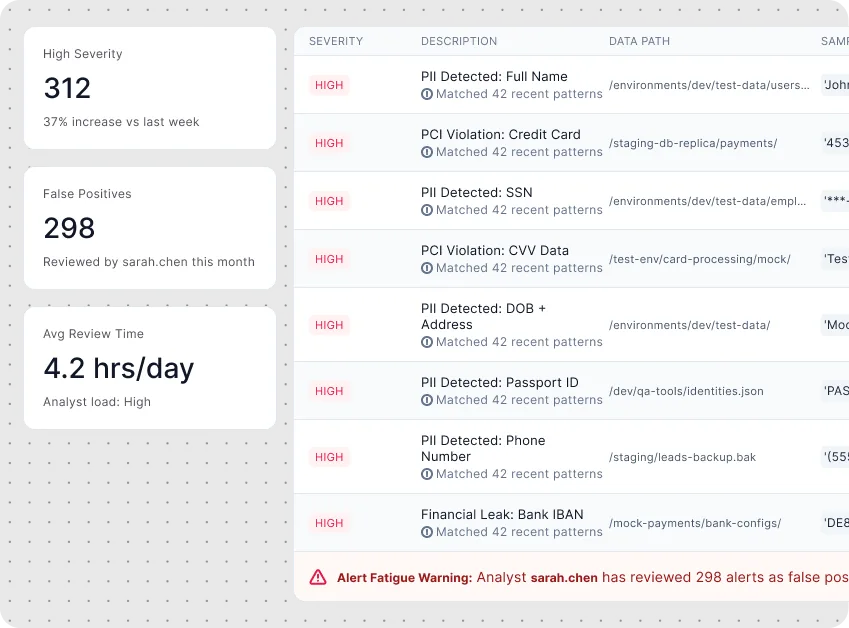
Teleskope can be configured to understand your environment's data boundaries — which databases are test, which are production, which are staging. This context is applied to classification so test data containing realistic-looking sensitive fields is not treated as production risk. This eliminates one of the largest sources of false positive fatigue in data security programs.
Teleskope monitors your environment continuously — new data is classified as it appears, modified data is reclassified as it changes, and deleted data is removed from the map. The data map reflects your current state, not the state from your last scheduled scan. This matters particularly for AI environments where data moves and changes rapidly.
Teleskope is built for large-scale unstructured data environments: it doesn't rely on sampling approaches that introduce false negative risk by not scanning every file. Every file is scanned. Classification runs continuously. Scale is handled through Teleskope's architecture, not managed by reducing coverage.
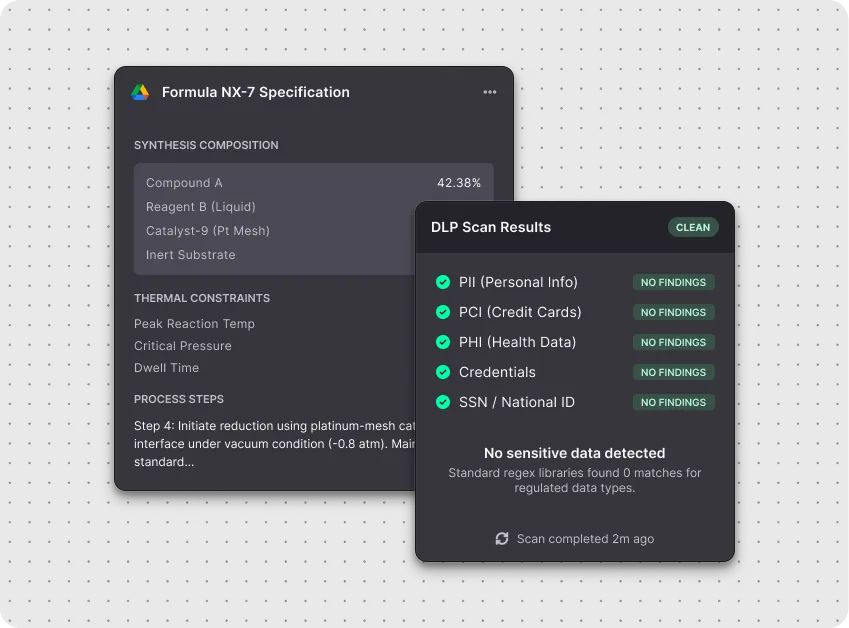
Prism is Teleskope's document intelligence capability — it classifies sensitive documents as a whole, not just the data fields they contain. Prism identifies sensitive documents by understanding what they are and what they mean in your business context, and can identify similar sensitive content based on known examples without requiring predefined rules. It's how Teleskope classifies IP, legal documents, and business-critical content that no regex will ever find.