
TL;DR:
Data remediation is the process of fixing, securing, or removing exposed sensitive data and requires moving beyond discovery into automated enforcement actions like access revocation, deletion, and redaction. Building an effective strategy means prioritizing risks by business impact, choosing automation that's flexible enough to reflect your risk appetite, and favoring native enforcement over clunky integrations. Measure everything: mean time to remediation, recurrence rates, and findings resolved within SLA. As you expand automation, classification accuracy becomes critical because in an automated workflow, a misclassification can trigger the wrong action.
Most security teams have an idea of where their sensitive data risks might be, but fixing them is a different story. Data remediation is the actual work of resolving exposed, overshared, or noncompliant data and is where most organizations stall. Scanners flag thousands of issues, dashboards turn red, and tickets pile up. Meanwhile, breaches like the Mercor AI incident (4 TB of data stolen) prove that unresolved exposure doesn't wait for anyone.
This guide covers how to build a data remediation strategy that drives real risk reduction. You'll get a step-by-step remediation plan, a clear breakdown of the process from discovery through enforcement, and practical criteria for evaluating data remediation tools.
What Data Remediation Is and Why It Matters
Data remediation is the act of fixing, removing, or securing data that poses a risk to your organization. That means revoking overly permissive access, deleting redundant sensitive files, encrypting exposed records, or redacting PII from systems where it shouldn't exist. It's the difference between knowing you have a problem and actually resolving it.
For CISOs and security leaders, data remediation is central to every compliance framework, breach-prevention effort, and AI governance initiative. Without it, discovery and classification are just expensive exercises in awareness.
The Real Cost of Unremediated Data Risk
When sensitive data exposures go unresolved, the consequences compound fast. Unremediated risks increase your attack surface every day they persist. Exposed PII in a shared Google Drive folder, stale API keys sitting in a Slack channel, customer health records in an unencrypted S3 bucket… Each one is a breach waiting to happen.
The financial hits from breaches are well documented, but the operational cost of not remediating is harder to quantify and often larger. Security teams burn hours triaging alerts that never get resolved. Legal and compliance teams scramble during audits because there's no auditable trail of corrective action. And when regulators come knocking after an incident, “we knew about it but didn't fix it" is the worst possible answer.
The gap between identifying a data risk and resolving it is where breaches are born. Every hour of delay is an hour of exposure.
This is exactly why tying data access governance directly into your remediation workflow matters so much. If you can't control who has access to what and revoke that access automatically when risk is detected, you're always playing catch-up.
{{banner-large="/banners"}}
Why Visibility Alone Doesn't Cut It
Scanning and classifying data doesn't reduce risk by itself. You can have perfect classification across every cloud environment, every SaaS app, every on-prem database, and still be fully exposed if nothing gets fixed. Many tools on the market do the “finding" part well but leave the actual remediation to you, your team, and a mountain of Jira tickets.
That's what makes a real data remediation strategy essential. Reducing risk must align with business goals and go beyond loss avoidance. A data remediation process that connects discovery directly to automated enforcement (access revocation, deletion, or data redaction) is what actually moves the needle on risk reduction.
Common Causes of Data Issues That Trigger Remediation
Most data risks build up quietly through everyday workflows, permission drift, and tools your security team never approved. Here are the three biggest culprits.
Data Sprawl and Overly Permissive Access
Your attack surface grows every time someone shares a Google Drive folder with “anyone with the link" permissions, creates a public Slack channel with customer details, or copies a production database into a staging environment. Data sprawl is the natural consequence of collaboration-heavy organizations. Files get duplicated across Teams channels, SharePoint sites, and personal cloud storage. And the access permissions? They almost never get tightened after the initial share.
The real issue is that overly permissive access compounds over time. A folder shared with “everyone in the domain" three years ago still grants access to every new hire. An external contractor who left the project six months ago can still view sensitive financial models. Without a data remediation process that continuously detects and corrects these permission issues, you're essentially leaving doors open and hoping nobody walks through them. Being able to discover and classify all of your data is the first step toward understanding where those open doors actually are.
Redundant, Obsolete, and Trivial (ROT) Data
These are the expired reports nobody reads, the duplicate customer records spread across four different systems, and the test datasets containing real PII that were supposed to be temporary. Every piece of ROT data increases your compliance burden and your breach blast radius without providing any business value.
A solid data remediation plan must include retention enforcement and automated cleanup of stale assets. Otherwise, your team ends up spending its limited bandwidth protecting data that should have been purged months ago.
Shadow Data and Unmanaged AI Workflows
This is where things get especially tricky. Employees paste customer conversations into ChatGPT for summarization. Data scientists spin up Jupyter notebooks with production datasets. Teams exports sensitive records to CSV files that reside on local machines. None of this shows up in your official data inventory.
Shadow data has always been a challenge, but the adoption of generative AI tools has dramatically accelerated it. Data breaches tied to employee actions have been surging, and unmanaged AI workflows are a growing contributor. When sensitive information flows into external AI services or gets embedded in model training pipelines without governance, data remediation becomes exponentially harder because you first have to find what you didn't know existed. This is exactly the kind of risk that AI security and governance frameworks are designed to address.
How These Causes Compare in Terms of Remediation Complexity
The table below breaks down each root cause by its detectability, the typical remediation approach, and the time manual fixes tend to take. It's a useful reference for prioritizing where to focus your efforts first.
Each of these causes demands a different data remediation approach, but they all share a common thread: waiting for a human to manually fix every issue doesn't scale. That's exactly why your strategy needs to account for automation from day one.
Building a Data Remediation Strategy That Actually Works
A data remediation strategy that delivers real outcomes needs structure, clear ownership, and automation baked in from the start. Here's how to build one step by step.
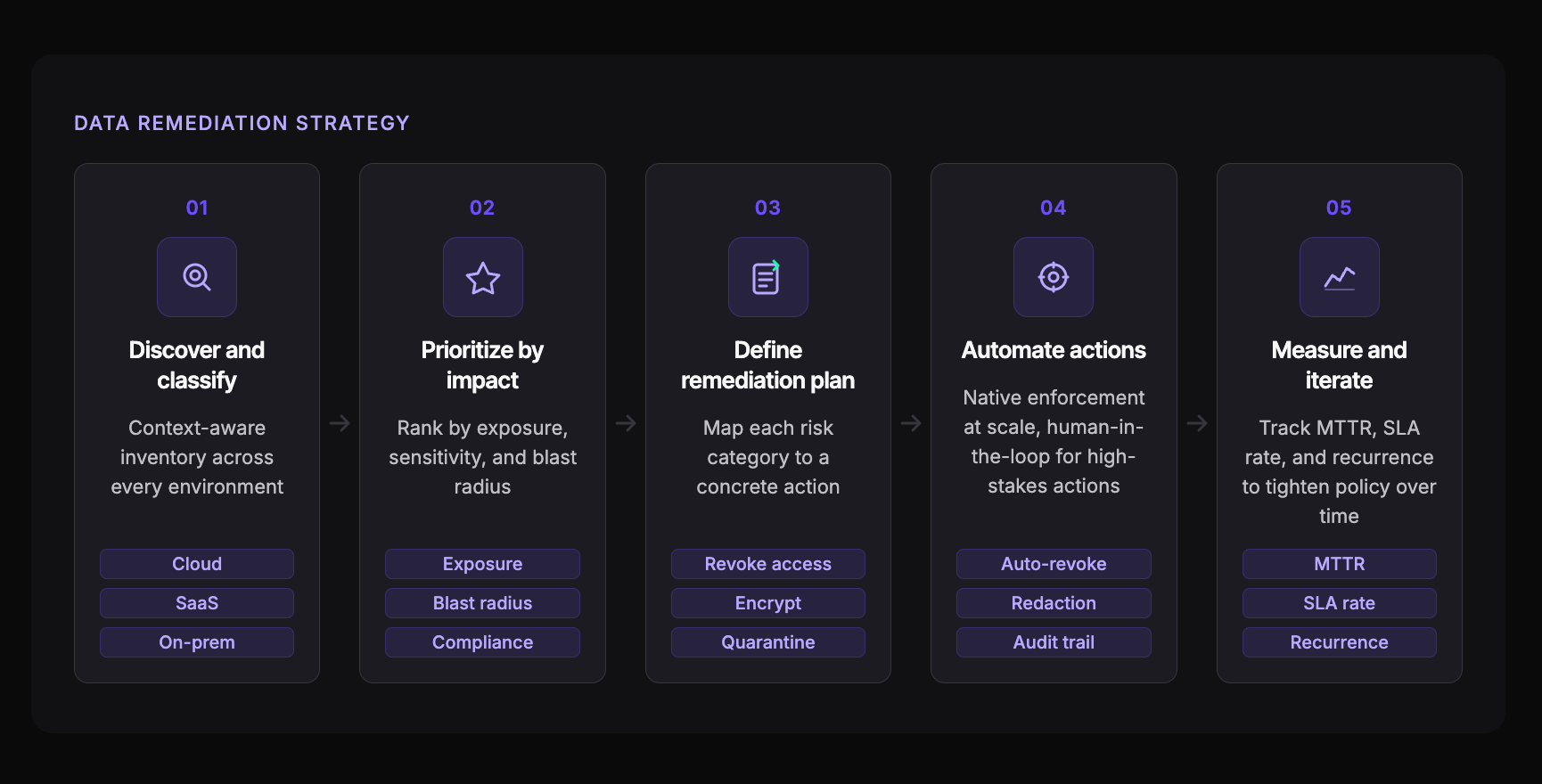
Step 1: Discover and Classify What You Have
Any good data remediation strategy starts with a thorough inventory of sensitive data across every environment your organization touches: cloud storage, SaaS applications, on-prem databases, and, yes, those Jupyter notebooks your data science team spun up last quarter.
Classification needs to go beyond simple regex pattern matching. You want context. Is that SSN sitting in a customer support ticket, a test dataset, or a production database? The answer changes everything about how you prioritize the fix. Tools like data classification as a service can help you get that contextual view without burning through your team's bandwidth.
Step 2: Prioritize Risks by Business Impact
Once you have a classified data map, resist the temptation to treat every finding equally. A publicly shared Google Drive folder containing PCI data poses a different risk than an internal SharePoint page with employee names. Your data remediation strategy should rank findings by exposure level, data sensitivity, regulatory implications, and blast radius if that data were breached.
This is where most teams get stuck. They try to boil the ocean instead of focusing on the exposures that would actually cause material damage.
Step 3: Define Your Data Remediation Plan
With prioritized risks in hand, you need a concrete data remediation plan that spells out what action to take for each category of finding. Here's a straightforward framework for mapping common risk categories to their recommended remediation actions:
- Overly permissive access: Revoke public links, enforce least-privilege policies, and remove stale external sharing permissions immediately for any file containing regulated data.
- ROT data with sensitive content: Assign data ownership, enforce retention policies, and delete or archive assets that have exceeded their lifecycle, especially duplicates spread across multiple systems.
- Shadow data in AI workflows: Quarantine sensitive files flowing into GenAI tools, apply redaction policies to exposed PII, and establish governance guardrails for any new AI-related data pipelines.
- Unencrypted sensitive records: Encrypt at rest and in transit, or relocate to approved secure repositories where policy enforcement is already in place.
Step 4: Automate the Data Remediation Process
If your data remediation process depends on humans manually executing every fix, it won't scale. Automate access revocation, scheduled deletion of expired data, and real-time redaction wherever possible. Reserve human-in-the-loop approval for high-stakes actions that require a second pair of eyes.
When evaluating automation solutions, flexibility matters as much as coverage. The right tool should let you configure enforcement to match your organization's risk appetite and policies, not force you into a one-size-fits-all ruleset. Teleskope, for example, lets teams define exactly which actions trigger automatically and which require approval.
Native automation versus integration-based automation is another consideration that you need to get right. Tools that rely on third-party integrations to execute remediation are clunky, prone to breaking during updates, and offer limited control. Native automation, where discovery, classification, and enforcement happen in a single system, is faster, more reliable, and easier to audit.
Automation isn't about removing humans from the loop. It's about freeing them to focus on decisions that truly require judgment, rather than on repetitive ticket closures.
Step 5: Measure, Audit, and Iterate
Track metrics that reflect actual risk reduction: mean time to remediation, percentage of findings resolved within SLA, volume of sensitive data deleted or secured per cycle, and recurrence rate of previously remediated issues. Every action should be auditable and reversible, both for internal accountability and regulatory proof. Review these metrics quarterly, adjust your data remediation plan based on what's recurring, and tighten automation rules as confidence grows.
{{cs-1="/banners"}}
How Teleskope Turns Data Remediation Into an Automated Outcome
Not every security team is ready to flip a switch and automate everything on day one, and that's fine. The most effective implementations start small; for example, you can automate one high-confidence action like revoking public links to files containing PCI data and build from there. As your team gains confidence in classification accuracy and policy tuning, you expand the automation footprint. Teleskope is built for this progression, letting teams start with visibility and manual approvals and then incrementally hand off enforcement as trust in the system grows.
From Discovery to Action in a Single Platform
Teleskope combines continuous discovery, classification, and native enforcement into one platform. Its multi-model AI engine (combining ML and GenAI) identifies over 150 types of sensitive data, including PII, PHI, PCI, and secrets, across cloud, SaaS, and on-prem environments, with 99.3%+ classification accuracy that keeps improving. The latest architecture update delivers over 10% higher precision and over 38% higher recall, meaning fewer false positives and fewer missed findings. That accuracy matters for teams moving toward automated remediation because misclassifications don't just generate bad alerts; they trigger the wrong actions.
What separates Teleskope from tools that just surface findings is what happens after detection. The platform triggers remediation actions natively: You can access revocation, data deletion, redaction, encryption, and retention enforcement without requiring your team to copy findings into a ticketing system and manually chase each one down. You set the policies; Teleskope enforces them. Every action is auditable and reversible. This kind of closed-loop enforcement is exactly what moves the needle for teams looking to strengthen their data security posture management.
For AI governance specifically, Teleskope's Prism feature uses LLMs to summarize and categorize unstructured data, helping teams decide what's safe for AI training versus what needs to be quarantined or redacted. Its Redact API plugs directly into codebases to scrub sensitive data before it reaches AI inference or training pipelines, a capability that most data remediation tools simply don't offer. If you're building or fine-tuning AI models, this is worth a closer look through the lens of DSPM for AI.
Real-World Results: The Atlantic, Ramp, and Kyte
Here's how three organizations used Teleskope to turn their data remediation processes into measurable outcomes.
Hundreds of terabytes with manual labeling and deletion
Automated discovery, classification, and cleanup at scale
Replaced manual processes with seamless automated remediation
These are actual production deployments where data remediation went from a perpetual backlog to an automated, continuous process. If your team is stuck in the gap between knowing where the risks are and actually fixing them, book a demo to see how Teleskope handles it end to end.
{{cs-2="/banners"}}
Conclusion
Data remediation is the work that actually shrinks your attack surface. Scanning, dashboards, and tickets sitting in a queue don’t reduce risk on their own. The teams getting results are the ones treating remediation as a continuous, automated discipline. Classify with precision, prioritize based on real business impact, enforce policies without waiting on manual intervention, and measure everything. If your current tooling stops at showing you the problem, that's your bottleneck.
Take the strategy and plan outlined here and pressure-test it against your own environment. Figure out which root cause, whether that's sprawl, ROT data, or shadow AI workflows, is costing you the most exposure right now, and start there. One focused remediation win will do more for your risk reduction than another quarter of scanning reports that nobody acts on.



